* Product details and visuals have been generalized to respect organizational confidentiality.
TL;DR
As AI adoption accelerated across the organization, I designed AI-assisted features that condense a fragmented research workflow into a single comparison surface, resolve ambiguity through semantic matching, and prevent duplication — without disrupting how stewards already work.
Overview
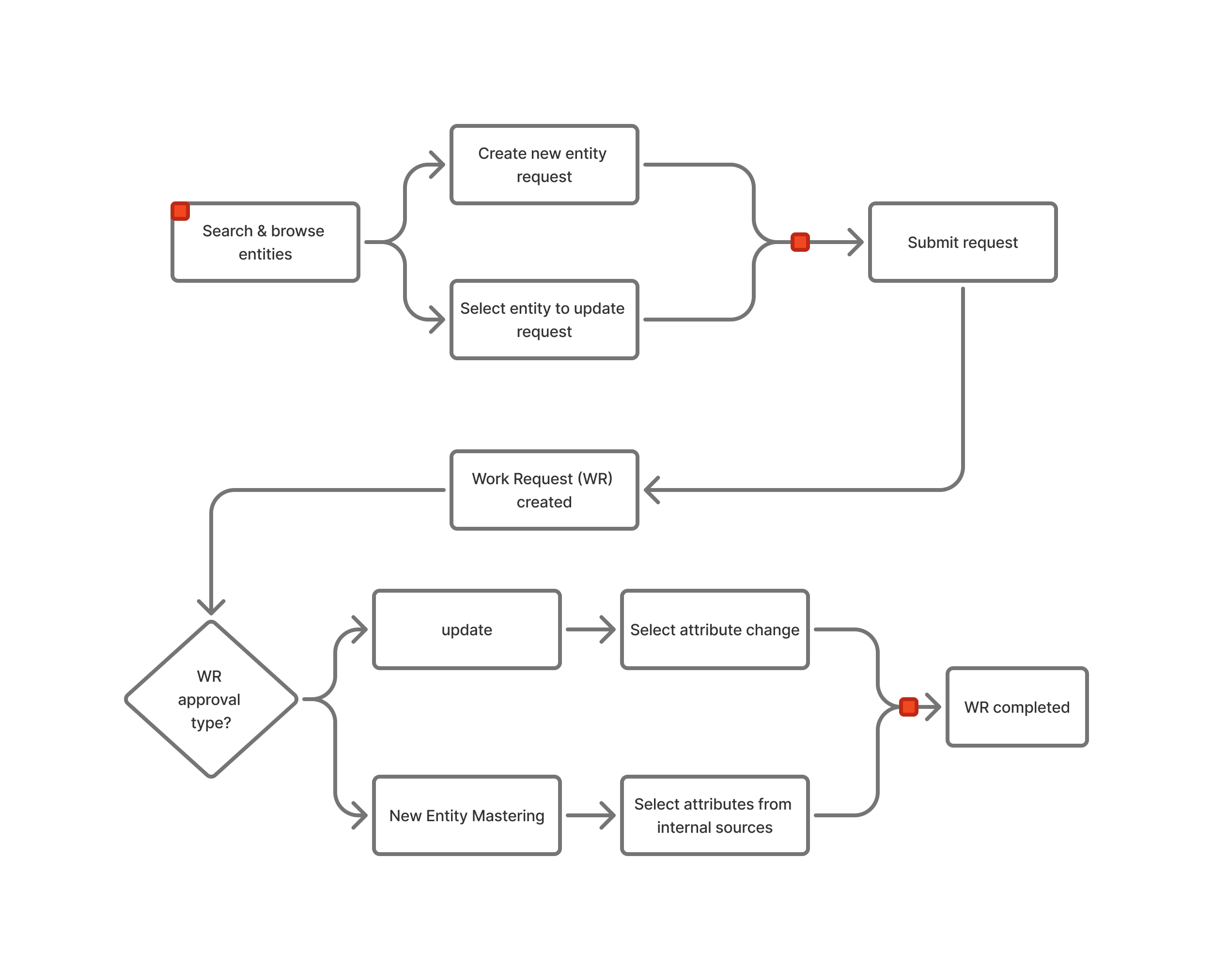
The platform is where data stewards, commercial teams, and relationship managers go to manage entity information. Users create new entities and update existing records through change requests. Once submitted, each request enters a worklist that requires approval—this applies to both entity changes and entity mastering before anything goes live.
Problem
⚠ Duplicate creation. Users submit new entity requests without knowing the entity already exists. The same entity gets created multiple times.
⚠ Fragmented research. Stewards compare entity data across three disconnected screens. Context disappears between steps, and custom values are free text with no audit trail.
Opportunity
✦ Semantic entity matching. The system surfaces potential matches so users catch duplicates before they propagate.
✦ Consolidated data enrichment. AI queries multiple external sources and aligns results in a single comparison view — row by attribute, column by source.
Interaction Model
The key design constraint: AI proposes, but the user always decides. Three actors, clear boundaries.
AI
Retrieves, matches, and proposes candidates
System
Validates against rules and schema
User
Reviews, selects, and commits — accountability stays here
What this meant for the UX
Suggest, never auto-commit. AI outputs are proposals. Nothing enters the system without explicit user confirmation.
Show provenance. Every AI-sourced value is attributable—users see where it came from, not just what it says.
Fit the existing flow. AI appears at moments users already act—before submission and during approval—not as a separate mode or tool.
Feature 1 · Semantic Retrieval
One retrieval engine powers three moments in the workflow. Instead of building separate experiences, the same semantic matching layer answers one question everywhere: "does this entity already exist?"
Click a numbered marker to learn more
Feature 2 · Entity Research & Resolution
Three separate screens — lookup, value selection, match check — with context lost between each step. I consolidated them into a single surface where comparing attributes and resolving entities happen on the same page.

Value selection
Every source in a column, every attribute in a row. Click a cell to select its value — a consensus badge surfaces agreement at a glance.

Source priority by column order. Authoritative registries left, supplementary sources right.
Third-party sources in a flyout. Secondary sources grouped behind a side panel — unlimited integrations without horizontal sprawl.
Structured override, not free text. Custom entries require a reason and reference. Overrides show an amber badge inline — visible to reviewers, not buried in logs.
Entity resolution
Potential matches surface inline after value selection. The steward resolves through one of three paths:

Link and enrich. Match to an existing entity and apply selected attributes — resolution doubles as data quality improvement.
Link as-is. Match without modifying the existing record.
Create new entity. No match fits. A new entity is created from selected values.
Reflection
Condensing three steps into one wasn't a compression exercise — it required reframing the task around attribute-level comparison and keeping resolution in the same context. In enterprise data tools, the design leverage is often in how information is structured, not in the interaction mechanics layered on top.